
In this article, you’ll learn what model-based design is all about—the drawbacks and advantages—illustrated through real-life examples. We’ll see:
- What model-based design is
- An example of a model-based design approach for a low-pass filter
- When to use model-based design
- The drawbacks of model-based design
What is Model-Based Design?
The model-based design approach consists of designing models using elementary blocks and using these models as a basis for the development of embedded software.
This means working with models as opposed to working with code (e.g. debugging, designing the architecture, reducing the complexity, testing) and generating the code from them.
This approach aims to reduce the costs associated with testing. With this approach, you test earlier rather than later in the development.
Using a model-based design approach makes it easy to create tests associated with a model early in a project. There exist powerful tools that generate tests automatically, thereby making it easy to test the development of your embedded software early and robustly.
The key idea here is to generate automatically the embedded code from the model, resulting in code that perfectly mirrors the model’s behavior.
How it Works: Example of a Low-pass Filter
Discrete Time Equation
Let’s take the example of a low-pass filter to illustrate the model-based design approach. One of the most common ways of describing a low-pass filter transfer function is the following:
\(H(s)=\frac{1}{1+\tau s}\)
From this transfer function stems the following equation:
\(H(s)=\frac{y(s)}{v(s)}=\frac{1}{1+\tau s}\\\\ y(s)(1+\tau s)=v(s)\\\\ y(s) + y(s)\tau s=v(s)\\\)
Which in discrete time gives (\(y(s)s\) as the equivalent of the derivative of \(y(s)\) in discrete time):
\(y[n] + \frac{y[n]-y[n-1]}{n-(n-1)}\tau=v[n]\\\\ y[n] + y[n]\tau-y[n-1]\tau=v[n]\\\\ y[n](1+\tau)=v[n]+y[n-1]\tau\\\\ y[n]=v[n]\frac{1}{1+\tau}+y[n-1]\frac{\tau}{1+\tau}\\\)
Using the equation above, we could implement this equation in C-language, for example.
However, using C would restrict the project to that specific language for everything that uses your low-pass filter. So, how can we add a layer of abstraction in order to avoid using a specific language?
Creating a Model
The answer is not to use a language at all. You use a model, test it, debug it, make sure the behavior is as you want and only then do you specify the language required for your embedded software and automatically generate the code from it.
Here is what the model associated with the discrete equation of a low-pass filter would look like in MATLAB & Simulink:
Equation:
\(y[n]=v[n]\frac{1}{1+\tau}+y[n-1]\frac{\tau}{1+\tau}\\\)
Model:
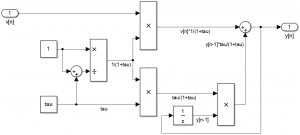
As you can see, creating a model once you have the discrete time equation is pretty straightforward:
- The output ( \(y[n]\)) is on the left of the model.
- The input (\(v[n]\)) is on the right of the model.
- The “+” block sums two signals.
- The “x” block multiplies two signals.
- The “\(\frac{1}{z}\)” block delays the signal from one step (from \(y[n]\) to \(y[n-1]\)).
It’s an intuitive way of creating a model based on a simple discrete time equation. This is where a significant part of the added value of the model-based design approach lies.
When to Use Model-Based Design
Finding Bugs Early
Since you can generate the tests automatically and test the models right away with this approach, you can find bugs earlier.
- Finding bugs early matters: Being able to identify and fix bugs very early in the development phase benefits your in both time and cost. Remember that you can run validation tests and debug the model in real-time. When you fix bugs early, the impact on the model’s behavior is easier to foresee and less risky because it is less entangled with the other parts of the model.
- Using continuous integration: This approach makes the continuous integration process (i.e. performing tests on a weekly or daily basis to identify the impact of modifications on the model’s behaviors) easy to put in place since you can execute the tests on remote servers rather than on a physical component.
- Using regression testing: This approach also allows for regression testing which is the ability to run the same tests before and after a modification to verify that you did not degrade the performance of the system or introduced a bug.
Creating Test Cases
Often, it’s easier to run test cases on a model than on lines of code. For example, there are tools to generate test cases that cover most of the model.
In other words, they will be able to activate a lot of different parts of the model. Let’s say that for the output of your model to be true, it needs \(X\) and \(Y\) to be true. Here’s what the model would look like:
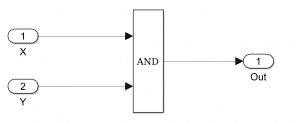
Then you need test cases describing the following:
- \(X\) is true and \(Y\) isn’t.
- \(X\) is false and \(Y\) isn’t.
- \(X\) and \(Y\) are false.
- \(X\) and \(Y\) are true.
Quite simply, with these four test cases, you fully cover the associated logic of the model. Then, you just have to compare the output of the model with what you wanted.
Obviously, if you don’t cover the model optimally, bugs might arise in real-world conditions. This is why important projects require high test coverage (measured in percentage).
In short, model based-design tends to be a good approach for coverage and code quality. For more information on this, see The Basics of Model-Based Design: On Documenting.
Model-Based Design Tools: the DRY Principles
Since you can manipulate and prototype models easily, many developers design models that already have code associated with it.
This would be in strict violation of the programming principle called DRY (“don’t repeat yourself”), which states that you shouldn’t do things twice or have unnecessary redundancies.
If you have unnecessary redundancies when you modify one thing you have to remember to modify the other redundant thing. (Of course, this is if you only have two redundancies for the same thing.)
As humans, we tend to forget. It makes sense that if there are redundancies, namely a piece of code and a model, we need an automated process to go from one to the other.
Unfortunately, there is no easy way to generate a model from code. That’s why it makes sense to use the model as a basis and not the code.
This supports several pieces of code from the same model, which means that if you decide to change the language of your embedded system, then you’ll just have to change the configuration of your model and generate the code in that new language.
Drawbacks of the Model-Based Design Approach
It Can Hide Issues if the Generation is Not Perfect
If the generated code doesn’t perfectly reflect the model’s behavior, some issues might arise from the model without appearing in the code. Even worse, they might arise in the code without appearing in the model.
Remember that you only analyze the model. If there are issues in the code but not in the model, you cannot see them. Thus, you need to run your test cases twice.
These issues are usually due to configuration errors in the model. That’s why establishing a standard model configuration is useful for a model-based design approach.
People are Not Used to This Approach
People who are used to coding in a particular language have developed a lot of tools specific to that language. Manipulating text and manipulating models are not the same things at all, and the tools that are used for one thing cannot be used for the other.
Sometimes, developers still develop using their preferred language. Because the industry standards are to code with a model-based design approach, the code is then used as a basis to design the models, which are then used to generate code again (sometimes in the same language in which it was originally coded).
The issues that can arise from this include bad architecture of the models, readability issues, size of the code, etc. The way to structure a model and to structure code in any other language differ greatly. For example, you can’t use objects, for-loops, or while-loops in the same way in C as in a model.
Not Everything is Easier with a Model-Based Design Approach
If you want to implement a for-loop, it is not as easy to code with a model-based design approach as in C-language, for example. This is a problem since it’s a very basic structure in every language and makes the transition from coding to designing models more difficult.
Similarly, with object-oriented programming, it is not easy to code with a model-based design approach either.
This makes the transition from coding to using models a dilemma without a straightforward answer. The benefits really have to outweigh the drawbacks to adopt this approach. It needs to be carefully studied on a case by case basis before making a decision.
Key takeaways:
- The model-based design approach consists of designing models using elementary blocks and using these models as a basis for the development of embedded software.
- You can automatically generate the embedded code from the model, resulting in code that perfectly mirrors the model’s behavior.
- This approach allows you to:
- Intuitively create models based on simple discrete time equations
- Find bugs earlier
- Use continuous integration
- Use regression testing
- Reduce redundancies of information
- Issues with the model-based design approach include the following:
- Test cases need to be run on the generated code and the models
- The tools are different and need to be re-built
- The architecture of the algorithms is different